Part 2
Inspection
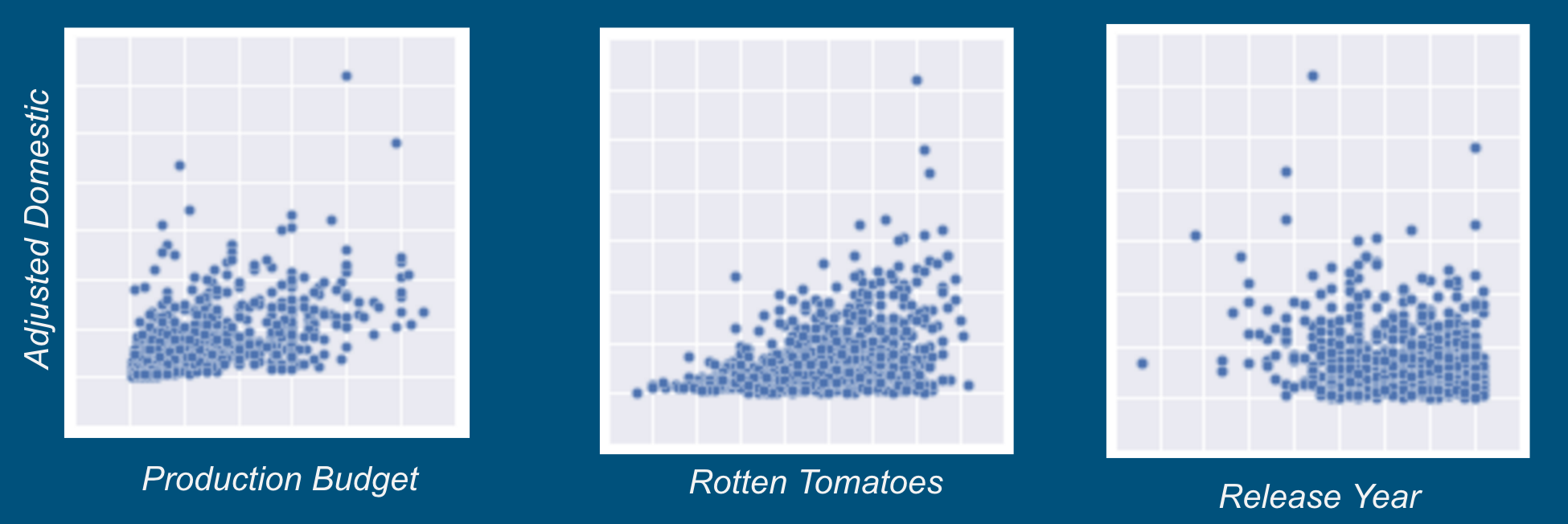
Before doing any modeling, I love investigating a seaborn pair plot of the data. The output shows the pair-wise relationship between all of the features. A couple examples can be seen in the figure below. Perusing through these plots is an awesome way to sanity check the collected data and look for any particularly interesting relationships. My objective was to predict domestic gross, and the pair plot built expectations for what features would be influential.
Lasso
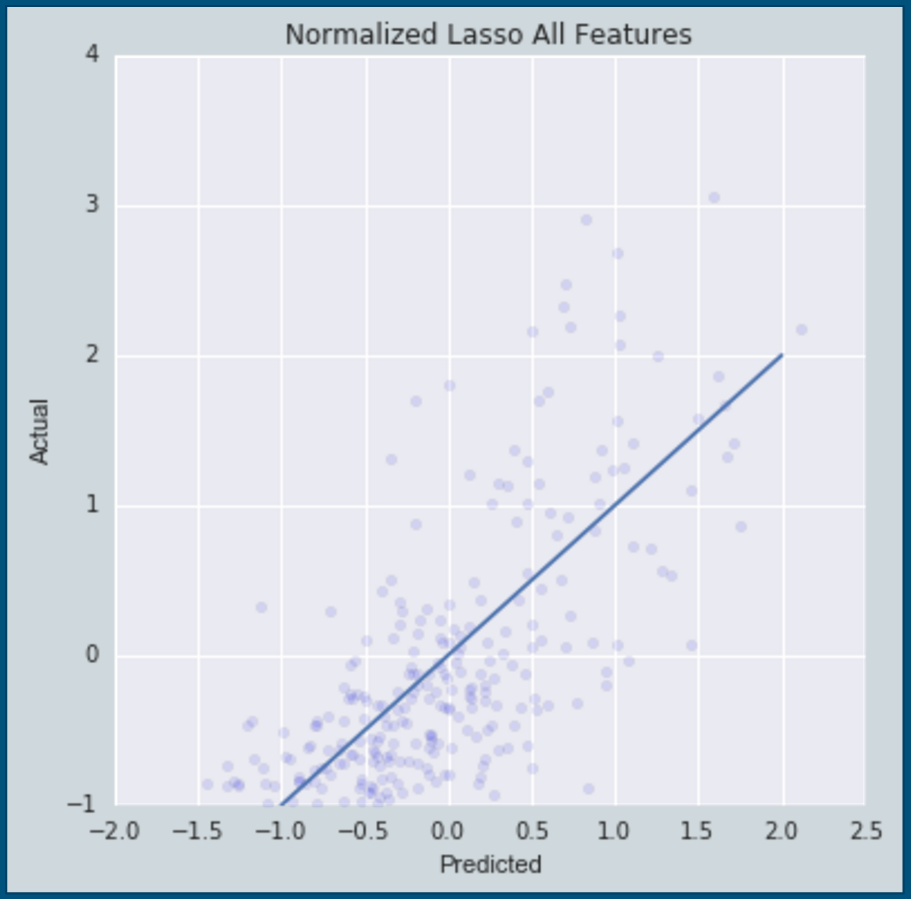
I filtered out all movies with missing values, then performed a 70-30 train-test split. My first pass regression model was done using a Lasso estimator on normalized values of all the features. The regularization of Lasso models helps prevent overfitting and excessive complexity. I’m also a big fan of using Grid Search for selecting optimal hyperparameters of any linear regression model. The model coefficients that mattered the most were production budget and ratings from IMDB and Rotten Tomatoes. The most interesting part of this exercise was learning that the Metacritic rating had essentially no value when making predictions. The figure below shows predicted domestic gross values vs. actual. A perfect model would plot every point on that straight blue line.
Testing on the Past 5 Years
Since the usefulness of a model is through accurately predicting future events, I thought it would be interesting to train on all films through 2010, and then predict revenues for films released from 2011-2016. I used the lasso regression model again, as well as random forest and gradient boosting tree approaches. An interesting outcome of the grid search methodology was discovering that the least absolute deviations (LAD) loss function performed better than the popular least squares function. Given the extreme outliers that occur in the film industry, this is not too surprising that the LAD function, which does not punish outliers as severely, would improve predictive power.
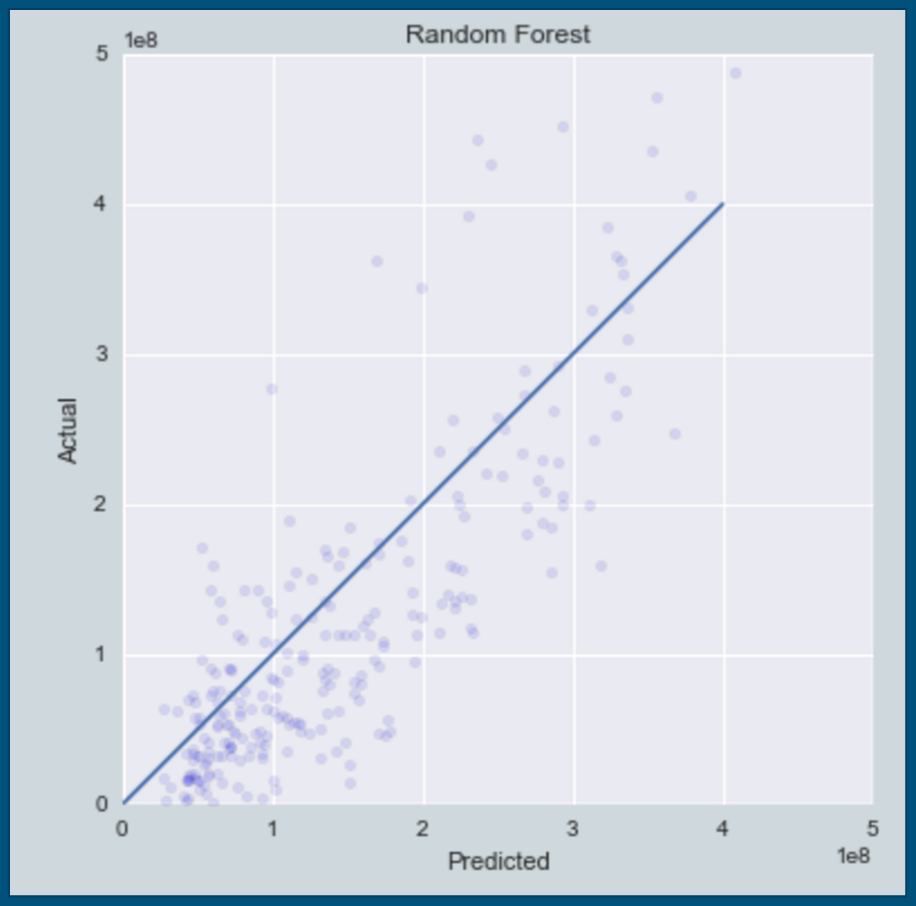
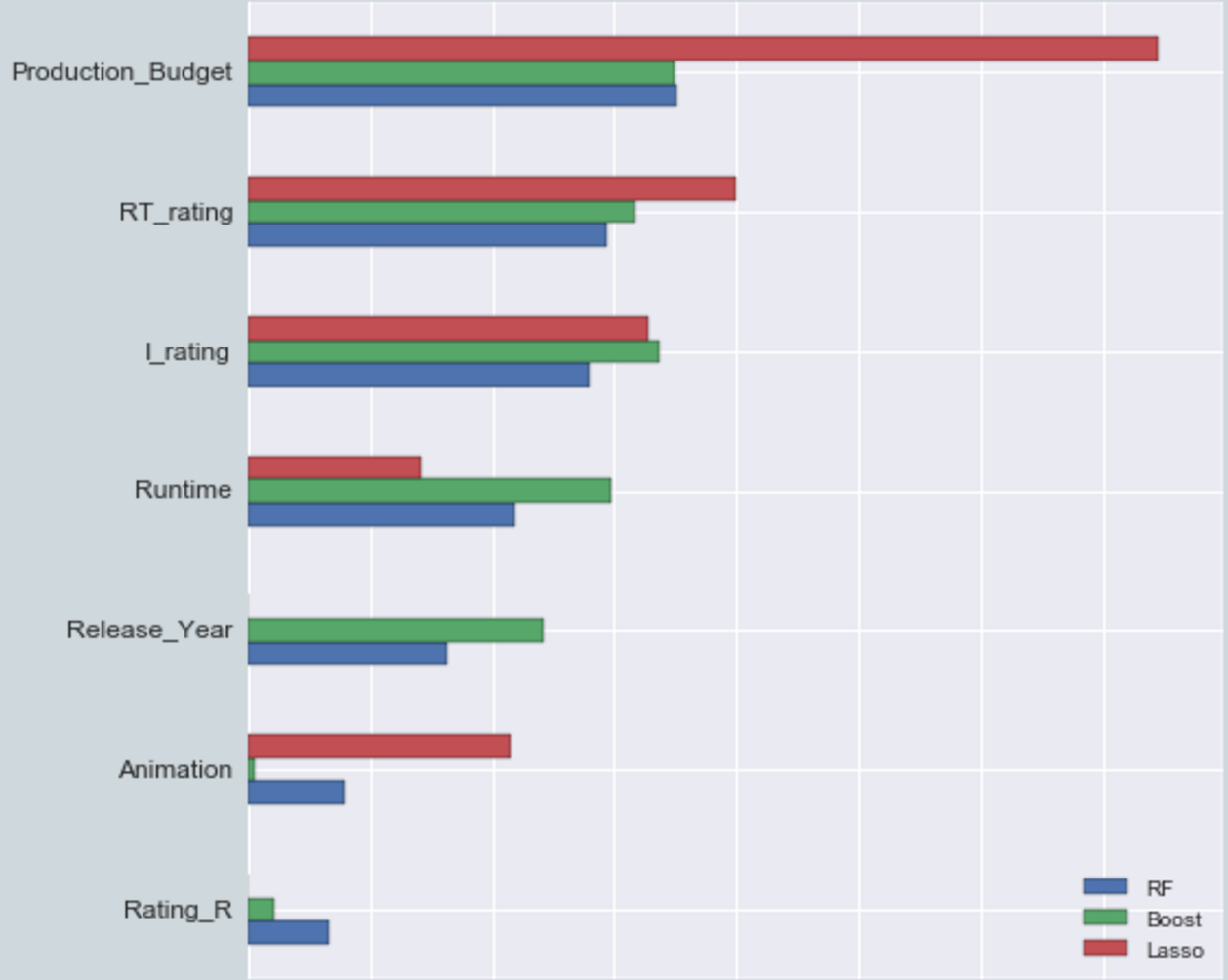
The random forest method, with test results shown above, performed the best. Below is a comparison of some of the more important features in each model. All of the models relied heavily on production budget and Rotten Tomatoes and IMDB rating. The genre of the film had very little influence in making predictions.
Notable Takeaways
The straight-up answer to my initial question is that no, genre on its own is not useful for determining how much a film is going to gross domestically. As one might expect, high budget films that people like are what make money. Despite these unexciting conclusions, I did make a few interesting discoveries, such as a 3D movies not being correlated with revenue in any model. I also found it important to be very careful about overfitting gradient boosted models when predicting on a new distribution. The moviegoing habits over the last 5 years were slightly different than the prior 30 years, which contributed to gradient boosting methods performing worse than anticipated. Attempting to predict the ratio of revenue to budget proved unsuccessful, mostly due to the presence of outliers and losing budget as a feature. Lastly, trying to make predictions within individual genres was unsuccessful, as most genres had only around 100 movies total, an insufficient number to generate meaningful conclusions.